Stable Diffusion メモ (6) Samplerごとの画風の傾向をつかもうとする
Sampler全然わからん
現時点(9/4)での想像・妄想・憶測
いろいろやって結局ようわからんかったので、いろいろやった結果として自分が出した現時点でのsamplerに関する自分の想像・妄想・憶測 *1 を書いておきます。
- Samplerごとに絵のタッチ、画風(?)に違いが出てくるものの、Samplerがxxxだからこのような出力になる、と説明することはできない
- promptによっても変わってくるので、いろいろ変えて試したうえで自分の好みの絵がよく出てくるSamplerに固定する、というのはアリかもしれない… が相当な沼にハマる恐れがある
- Samplerに関連してほかに絵が変わるパラメーターとしてはSampling Steps, CFG scaleもあり、最適な組合せを人間が探そうとするとえらいことになる
- いくつかのSamplerのうち、k_eulerはきれいな画像が得られるまでのSampling Stepsが少なくてすむという報告がいくつかあるため、画像の生成時間を短くする目的でk_eulerを採用するメリットはありそう
- txt2imgした画像の一部をimg2imgで修正する場合は、両方のSamplerを合わせた方が無難(画風を合わせるため)
この先を読み進めても、これ以上に得られるものはないかもしれません… が、出力結果のサムネを眺めているとなんか得られるものがあるかも?????
Samplerについてぐだぐだと
KritaのStable Diffusionプラグインで顔を書き換えまくっていたんですが、どうもタッチというか画風というか、が元絵と違うので浮く…


なんか方法はないものか、とSD Pluginのパネルを見ると、見慣れない「Sampler」というのがあるので、これかなぁといろいろ調べ… 
DDIMに設定すると、おータッチが合ってきた、気がする、のでこれでいこうということに。
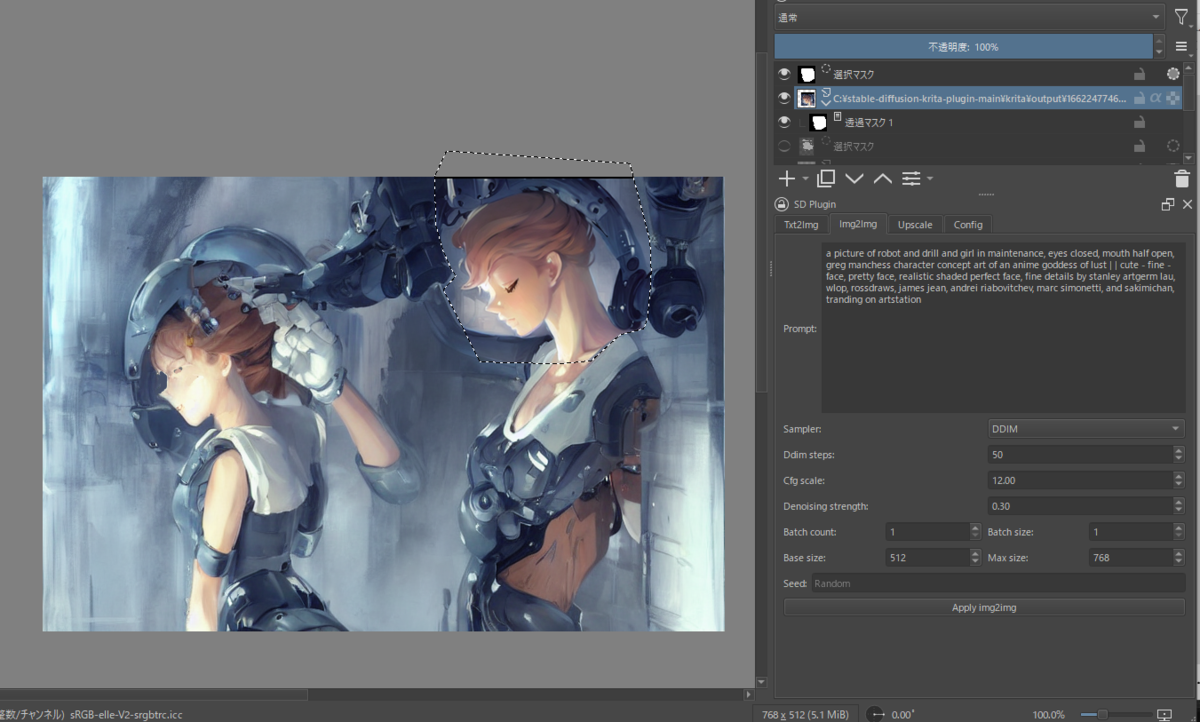
しかし、Samplerってまた新しいパラメーターが出てきたな… なんだこれは
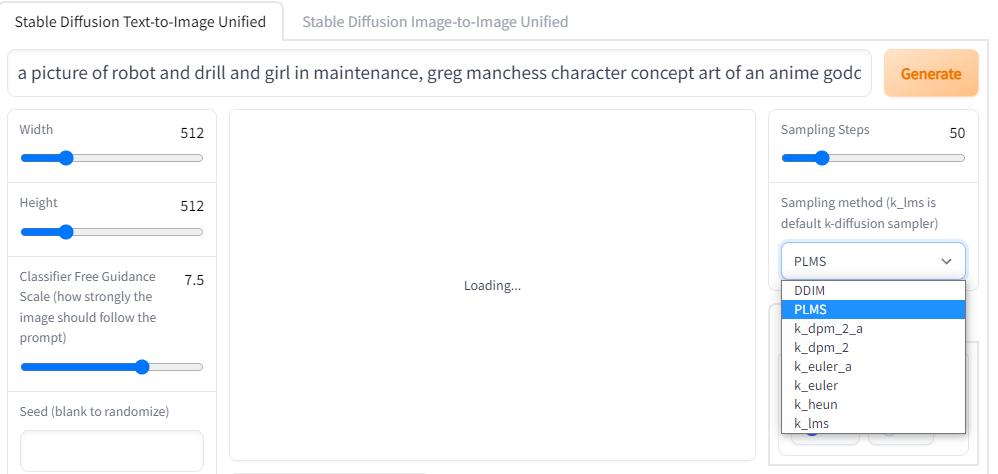
Samplerが選択できる実装
どうやら、Kritaのプラグインのfork元のこれ
にある、webui にはSamplerを指定できるUIがあるみたい。なるほど、自分は別のコードを使っていてSamplerを指定する機能がなかったから今まで知らなかったんだな…
Samplerとはなんぞや(自分はわからなかった)
そもそもSamplerってなんぞやというのは、こちらの記事を読むと
「画像生成のための反復ノイズ除去プロセス」のひとつ「Denoising Diffusion Implicit Models」(DDIM)が書かれいるため、まぁそういうことなんだろうと。すみませんよくわかりませんでした。記事にも
#DALLEや#StableDiffusionのような拡散モデルは画像生成の最先端ですが、それらがどのようにして動作しているかの理解はまだ始まったばかりです。
て書いてあるので、詳しい方の説明を待ちましょう……
でも先ほどの記事はStable Diffusionが何をやっているかの概要がよくわかる記事だと思いますよ! 素人の言うことなのでアレですが。
Samplerに関する出力結果(Reddit)
Reddit にそこそこあります。
いろいろ見てみると
- ほかと比べて明らかに生成された絵が違うSamplerがある
- Sampling Steps, CFG Scaleの値も生成結果に影響しそう
- k_eulerはきれいな画像が得られるまでのSampling Stepsが少なくてすむようだ
っぽいなぁというのはわかるものの、実際に手元で出力してみてどういう傾向があるのかためしたくなったのでやってみた。
やったこと
webuiで大量に絵を出すのは大変そうなので、先ほど上げたwebuiの実装のwebui.pyにある関数txt2imgをループして実行させる。呼びだし方はKritaのプラグインのこのあたりを参考にすればできそうだ。
これを、samplerごとにループして、
samplers = ['PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms']
seedの初期値を固定して、インクリメントしつつ50枚出力してみよう。
for j in range(1,50+1):
for index, sampler in enumerate(samplers):
output_images, seed, info, stats = txt2img(
prompt=prompt,
ddim_steps=opt['ddim_steps'],
sampler_name=sampler,
toggles=[1 if opt['normalize_prompt_weights'] else None,
2, # it's skip_save, without it webui will not output any image
4 if opt['use_gfpgan'] else None,
5 if opt['use_realesrgan'] else None],
realesrgan_model_name=opt['realesrgan_model_name'],
batch_size=opt['batch_size'],
cfg_scale=opt['cfg_scale'],
seed=1026820315 + j,
height=height,
width=width,
fp=None,
variant_amount=opt['variant_amount'],
variant_seed=opt['variant_seed']
)
こうすると、同一prompt, 同一seedごとにsampler8種の出力結果が得られるので、見比べることができる。
結果
実際の出力結果は下に貼り付けてあるので見ていただくとして(8 Sampler * 50 seed *3 prompt = 1200枚の画像のサムネが並んでおりますが…)、ざっと見た傾向として
- 明らかに k_dpm_2_a と k_eular_a は他のSamplerと比べると出力される絵が異なる
- その他のSamplerは正直似たり寄ったりというところがあるが、たまに細部の出力結果が異なってくることがある
- 絵のタッチがSamplerごとに異なる、ような気がする
Sampler単体をとっかえひっかえして評価するものではなく、他のパラメーター(主にSampling Steps, CFG Scale)と組合せて評価するもんなんでしょうなぁ、という印象でした。
長すぎるpromptは削ってる疑惑
一部のpromptで実行すると、コンソールの出力にwarningが出ています。

Warning: too many input tokens; some (6) have been truncated:
art , trending on artstation
とのこと カンマも一文字とカウントして70wordsを超えるwordは切り落とされるみたいだ こりゃカンマ削らないといかんマジで(渾身のダジャレ)
prompt 1
以下のパラメーターを固定する。
prompt:
Digital Matte painting. Hyper detailed. City in ruins. Post-apocalyptic, crumbling buildings. cyberpunk. Seattle skyline. Golden hour, dusk. Beautiful sky at sunset. High quality digital art. Hyper realistic.
Sampling Steps: 50
CFG scale: 7.5
以下の画像は上から seed: 1026820316 ~ 1026820365、右から Samplers = 'PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' と並んでいます。
もう面倒なのでサムネイルをキャプチャして貼り付けよう。本当は生の出力結果を並べて出せればいいんでしょうが… なんかいいやり方はないものかな













prompt 2
以下のパラメーターを固定する。
prompt:
beautiful stunning amazing slightly cloudly sky with various differently colored floating islands made of dirt and sand and stone with many varied rainforest forest desert plants and few little animals, landscape, fantasy, wide angle, sharp image, cinematic, concept art, 3d, photorealistic render, octane render, blender cycles, unreal engine, raytracing, volumetric light, photoshop, lightroom, digital art, trending on artstation
Sampling Steps: 50
CFG scale: 7.5
以下の画像は上から seed: 1026820316 ~ 1026820365、右から Samplers = 'PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' と並んでいます。







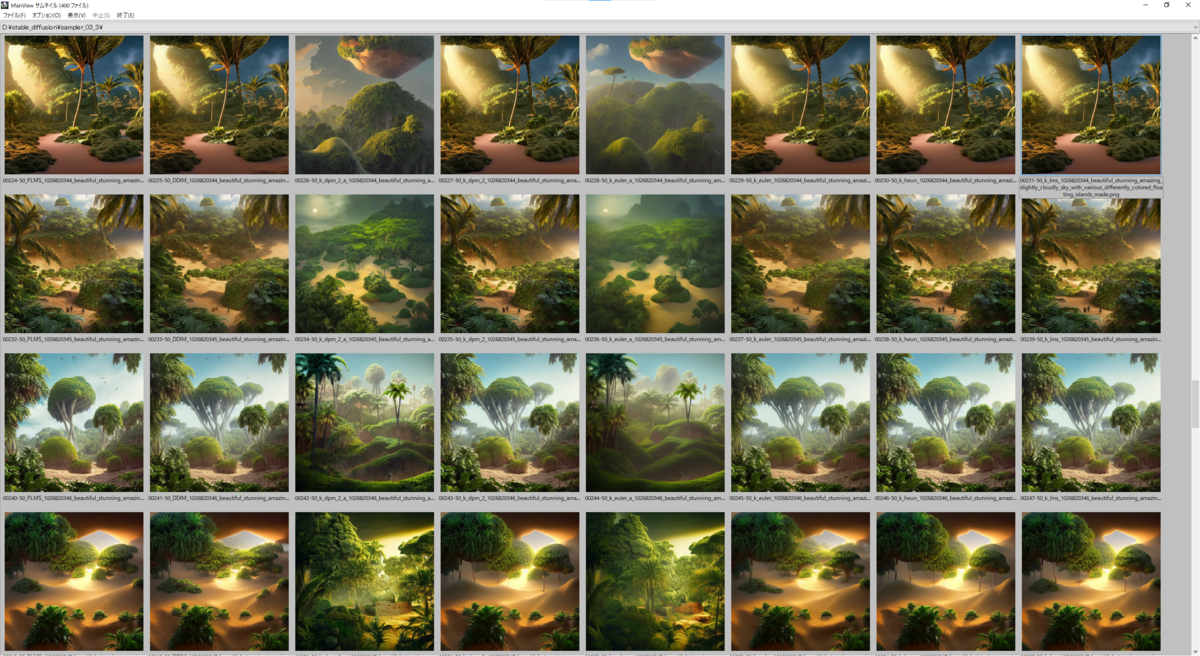


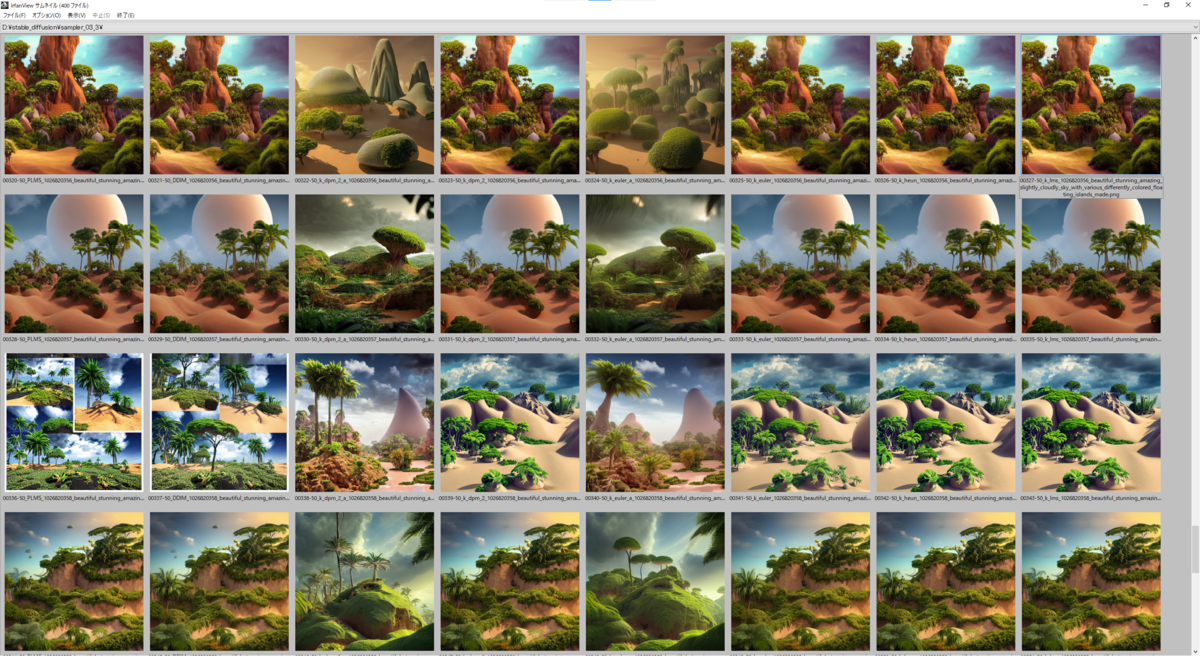


prompt 3
以下のパラメーターを固定する。
prompt:
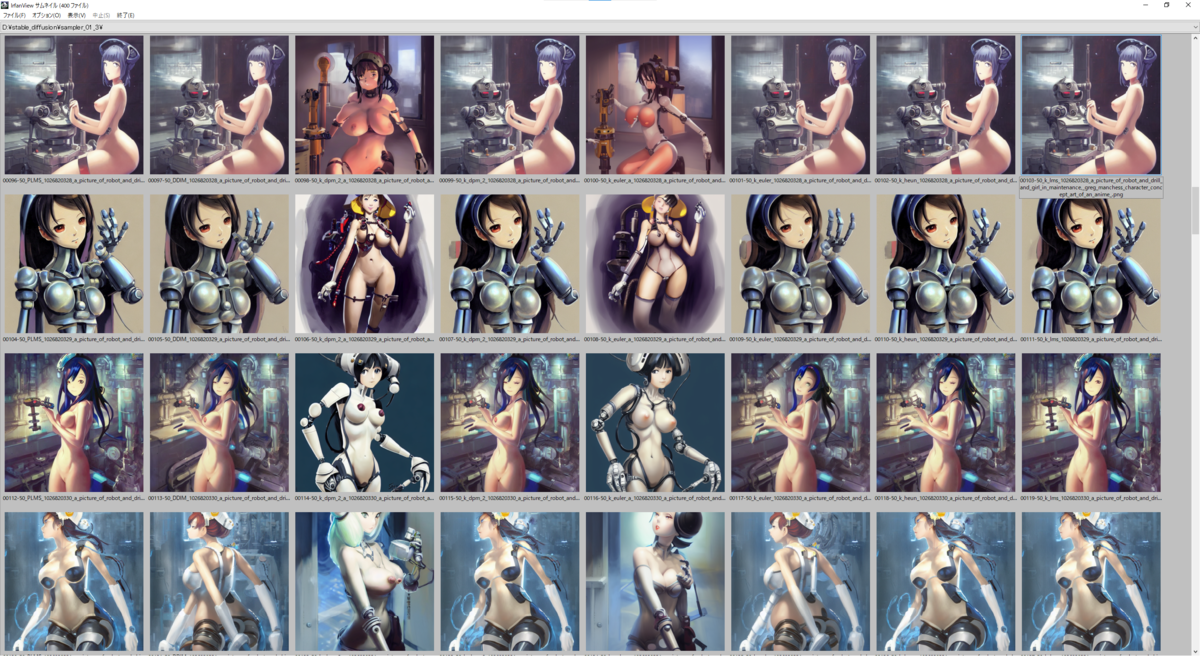
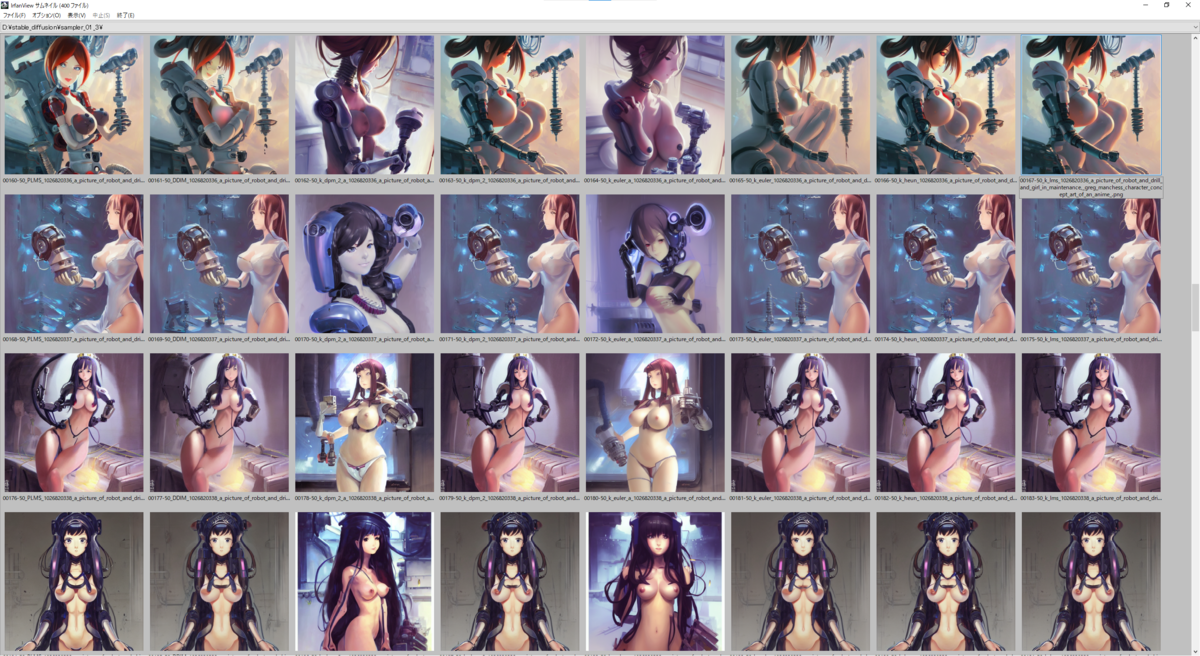
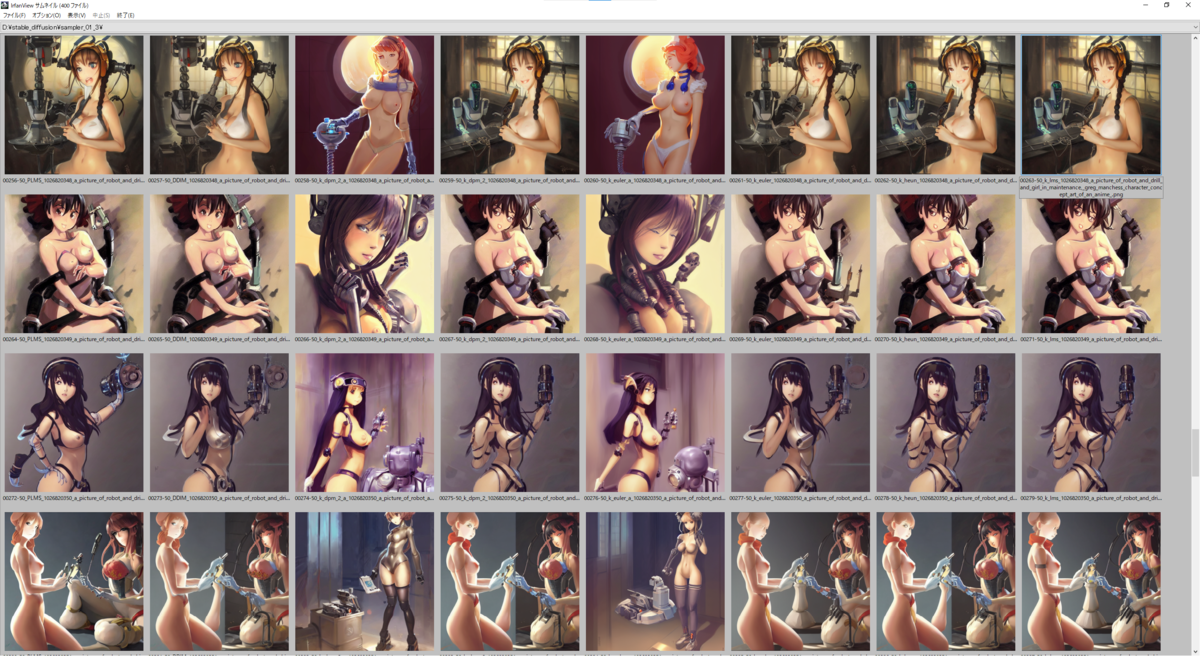
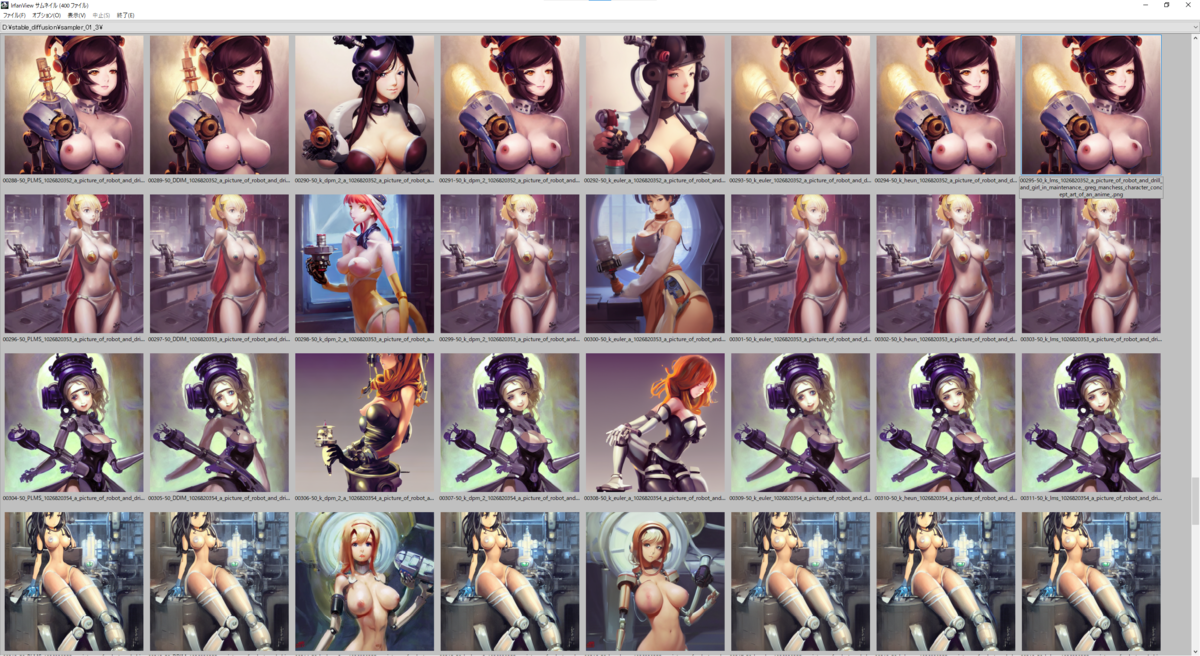
a picture of robot and drill and girl in maintenance, greg manchess character concept art of an anime goddess of lust | | cute - fine - face, pretty face, realistic shaded perfect face, fine details by stanley artgerm lau, wlop, rossdraws, james jean, andrei riabovitchev, marc simonetti, and sakimichan, tranding on artstation
Sampling Steps: 50
CFG scale: 7.5
以下の画像は上から seed: 1026820316 ~ 1026820365、右から Samplers = 'PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' と並んでいます。









*1:YouTuberの失敗小僧さんがよく言うセリフですが、なるほどこりゃあ便利な言葉だなぁ