Stable Diffusion メモ (7) promptの最大長について
prompt(一部では呪文という言い方もありますね)の最大長について、日本語で書いてある記事がなかったので調べて記録(あったらひとえに自分のググり能力の低さゆえ…)
ここに書いてある内容によると、
- prompt の長さは文字数ではなく、"token"という単位で数えられる
- prompt は 75 tokens 以下である必要がある。それを超えると切り捨てられる。
- "token"とは、大まかに言えば単語、句読点、Unicode文字である
とのこと。
なおtoken以外にもいろいろ書いてあって、prompt関連だと
- promptは大文字と小文字を区別しない
- AIが理解できるtokenは約3万個(これは1600年代から使われていない奇妙な単語を知らないことを意味する)
- 同じprompt、同じSeed、同じModifier(Width, Height, Sampling Steps, CFG Scale, Samplerなどなど) を指定すると同じ画像が出る
- このため絵をちょっと変えようと思ったらSeedを固定してpromptやModifierを少しずつ変えるのがお勧め
とのこと。へー、というかこのページ、各種情報のリンクとかめっちゃまとまってますな…
tokenってどうやって測るの
ようわからんけども、promptの文字列をどうtokenとして刻んでいくはどうもモデルによって決まっているらしい。
簡単な方法は、promptが長すぎると削ったことを警告してくれるUIを使うことだろうと思う。ローカルで動かす実装として自分が知っているのは↓のWebUIです。
このWebUIで絵を出力すると、promptが長すぎる場合にこのようなwarningが出ます。

warningが出なくなるまでtokenを削ればよいということになります、のでいろいろ試行錯誤しましょう。単語を削ったり記号を削ったり… warningは出なくなったけど絵が自分の好みではなくなったとかいう沼が待っているとかいないとか…
Stable Diffusion メモ (6) Samplerごとの画風の傾向をつかもうとする
Sampler全然わからん
現時点(9/4)での想像・妄想・憶測
いろいろやって結局ようわからんかったので、いろいろやった結果として自分が出した現時点でのsamplerに関する自分の想像・妄想・憶測 *1 を書いておきます。
- Samplerごとに絵のタッチ、画風(?)に違いが出てくるものの、Samplerがxxxだからこのような出力になる、と説明することはできない
- promptによっても変わってくるので、いろいろ変えて試したうえで自分の好みの絵がよく出てくるSamplerに固定する、というのはアリかもしれない… が相当な沼にハマる恐れがある
- Samplerに関連してほかに絵が変わるパラメーターとしてはSampling Steps, CFG scaleもあり、最適な組合せを人間が探そうとするとえらいことになる
- いくつかのSamplerのうち、k_eulerはきれいな画像が得られるまでのSampling Stepsが少なくてすむという報告がいくつかあるため、画像の生成時間を短くする目的でk_eulerを採用するメリットはありそう
- txt2imgした画像の一部をimg2imgで修正する場合は、両方のSamplerを合わせた方が無難(画風を合わせるため)
この先を読み進めても、これ以上に得られるものはないかもしれません… が、出力結果のサムネを眺めているとなんか得られるものがあるかも?????
Samplerについてぐだぐだと
KritaのStable Diffusionプラグインで顔を書き換えまくっていたんですが、どうもタッチというか画風というか、が元絵と違うので浮く…


なんか方法はないものか、とSD Pluginのパネルを見ると、見慣れない「Sampler」というのがあるので、これかなぁといろいろ調べ… 
DDIMに設定すると、おータッチが合ってきた、気がする、のでこれでいこうということに。
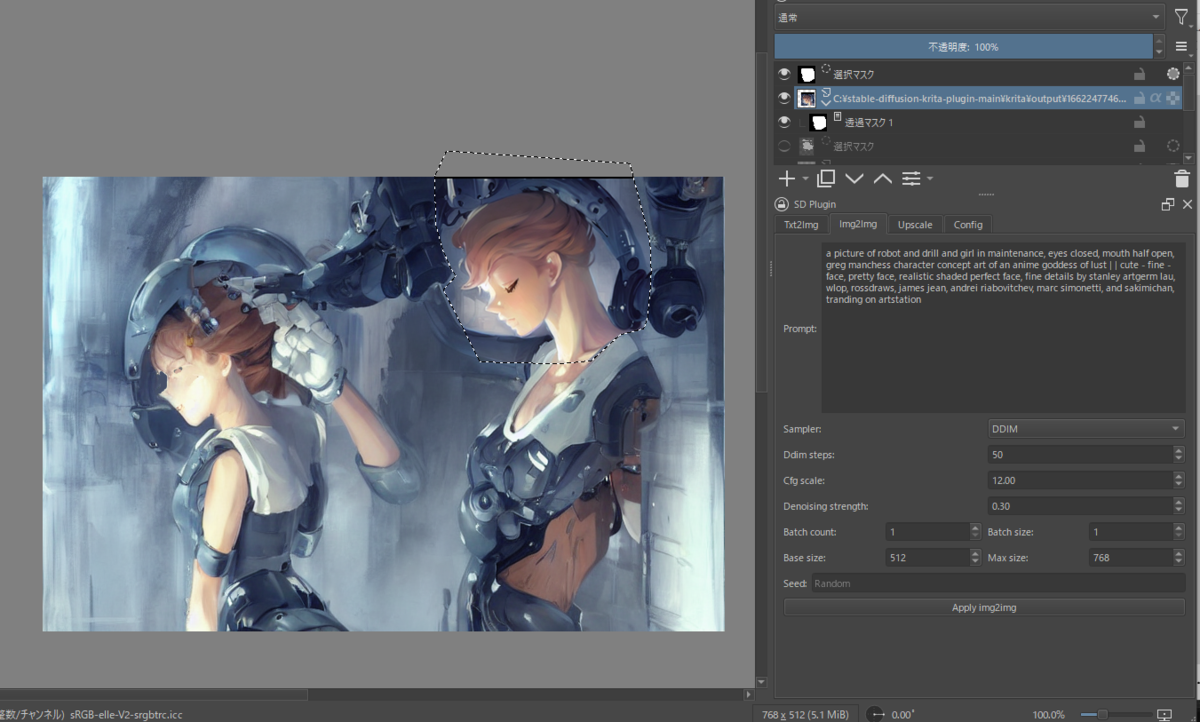
しかし、Samplerってまた新しいパラメーターが出てきたな… なんだこれは
Samplerが選択できる実装
どうやら、Kritaのプラグインのfork元のこれ
にある、webui にはSamplerを指定できるUIがあるみたい。なるほど、自分は別のコードを使っていてSamplerを指定する機能がなかったから今まで知らなかったんだな…
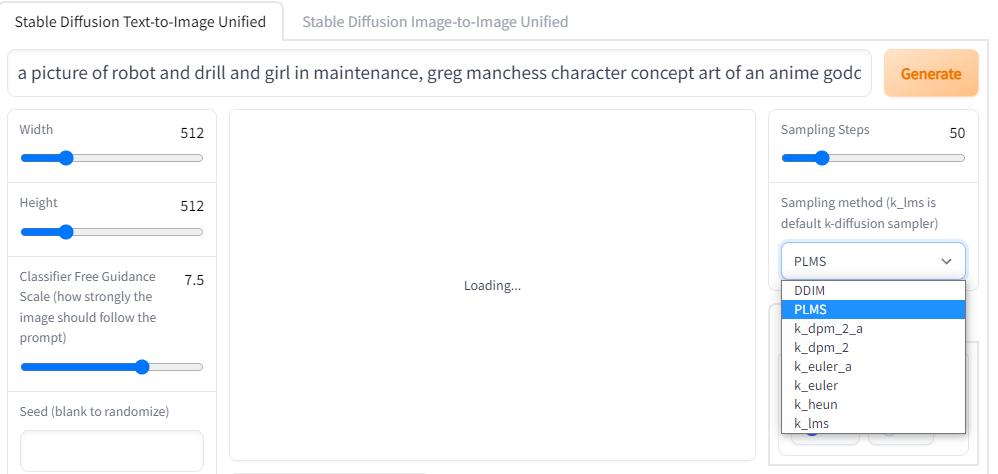
Samplerとはなんぞや(自分はわからなかった)
そもそもSamplerってなんぞやというのは、こちらの記事を読むと
「画像生成のための反復ノイズ除去プロセス」のひとつ「Denoising Diffusion Implicit Models」(DDIM)が書かれいるため、まぁそういうことなんだろうと。すみませんよくわかりませんでした。記事にも
#DALLEや#StableDiffusionのような拡散モデルは画像生成の最先端ですが、それらがどのようにして動作しているかの理解はまだ始まったばかりです。
て書いてあるので、詳しい方の説明を待ちましょう……
でも先ほどの記事はStable Diffusionが何をやっているかの概要がよくわかる記事だと思いますよ! 素人の言うことなのでアレですが。
Samplerに関する出力結果(Reddit)
Reddit にそこそこあります。
いろいろ見てみると
- ほかと比べて明らかに生成された絵が違うSamplerがある
- Sampling Steps, CFG Scaleの値も生成結果に影響しそう
- k_eulerはきれいな画像が得られるまでのSampling Stepsが少なくてすむようだ
っぽいなぁというのはわかるものの、実際に手元で出力してみてどういう傾向があるのかためしたくなったのでやってみた。
やったこと
webuiで大量に絵を出すのは大変そうなので、先ほど上げたwebuiの実装のwebui.pyにある関数txt2imgをループして実行させる。呼びだし方はKritaのプラグインのこのあたりを参考にすればできそうだ。
これを、samplerごとにループして、
samplers = ['PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms']
seedの初期値を固定して、インクリメントしつつ50枚出力してみよう。
for j in range(1,50+1):
for index, sampler in enumerate(samplers):
output_images, seed, info, stats = txt2img(
prompt=prompt,
ddim_steps=opt['ddim_steps'],
sampler_name=sampler,
toggles=[1 if opt['normalize_prompt_weights'] else None,
2, # it's skip_save, without it webui will not output any image
4 if opt['use_gfpgan'] else None,
5 if opt['use_realesrgan'] else None],
realesrgan_model_name=opt['realesrgan_model_name'],
batch_size=opt['batch_size'],
cfg_scale=opt['cfg_scale'],
seed=1026820315 + j,
height=height,
width=width,
fp=None,
variant_amount=opt['variant_amount'],
variant_seed=opt['variant_seed']
)
こうすると、同一prompt, 同一seedごとにsampler8種の出力結果が得られるので、見比べることができる。
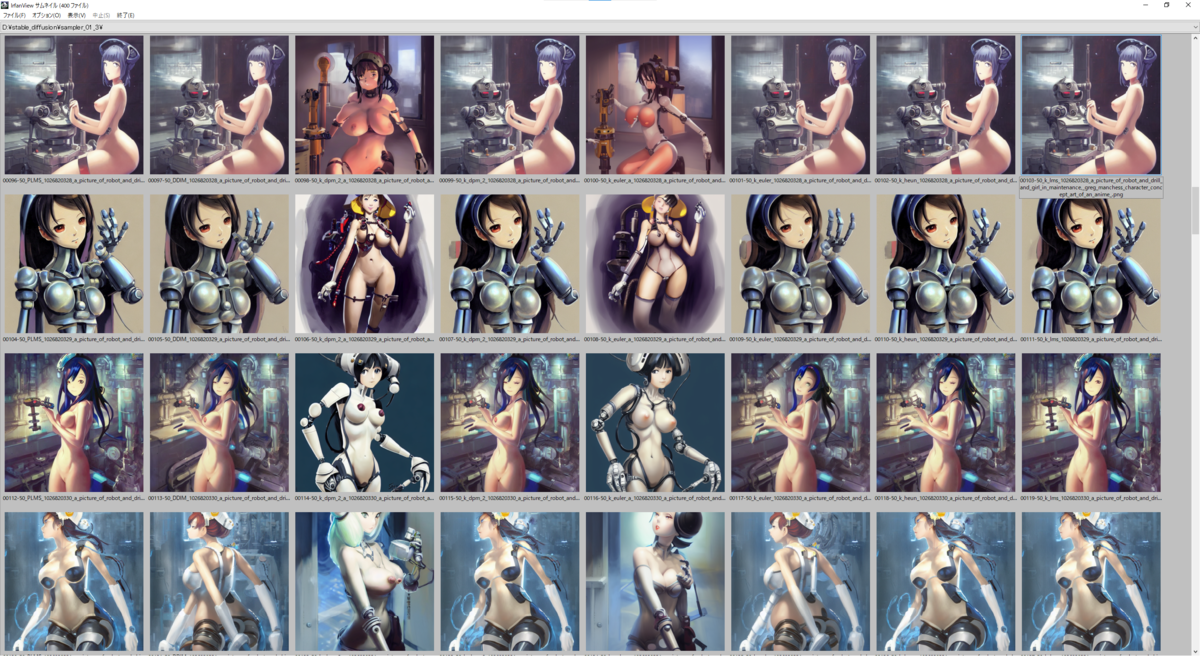
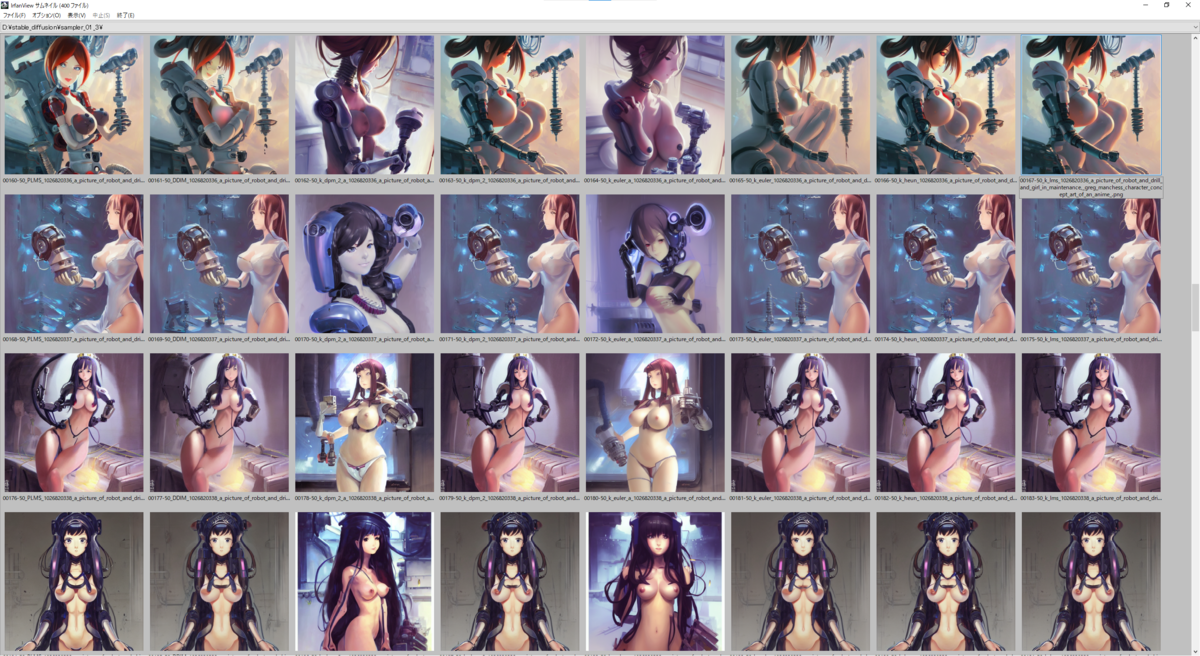
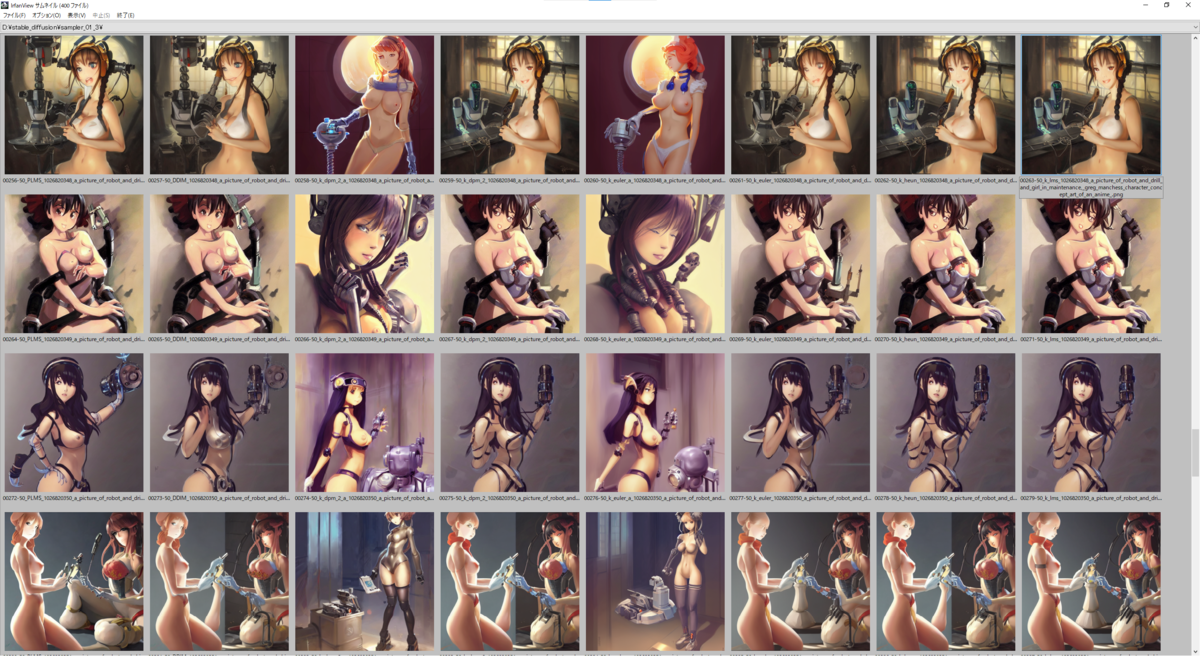
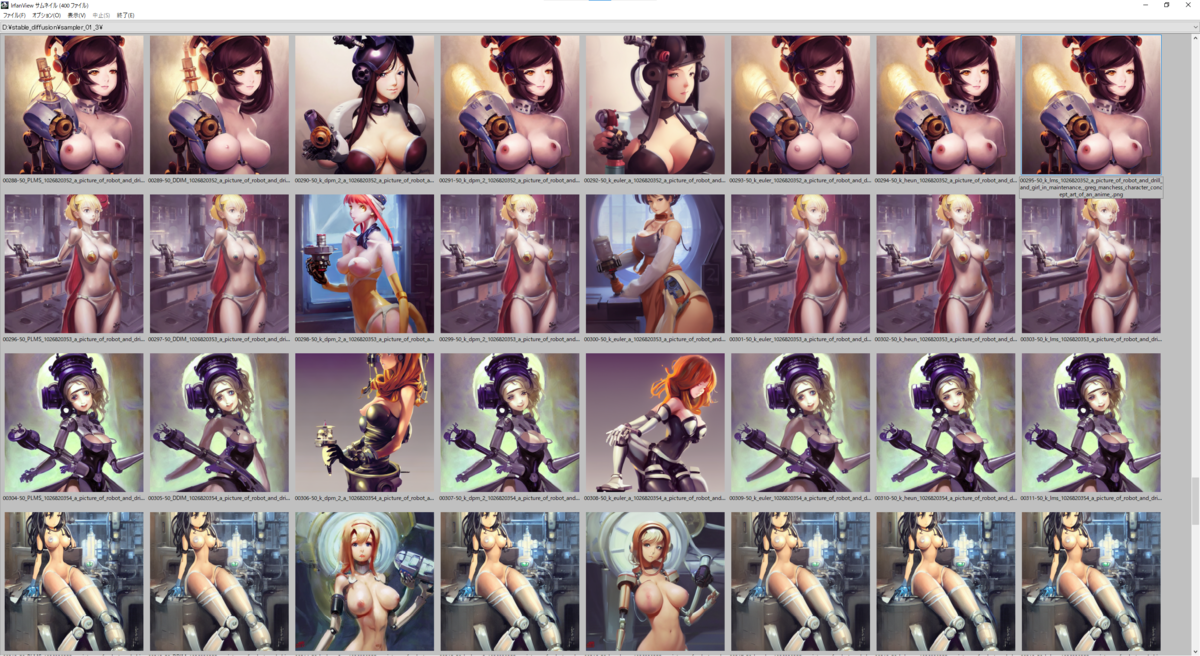
結果
実際の出力結果は下に貼り付けてあるので見ていただくとして(8 Sampler * 50 seed *3 prompt = 1200枚の画像のサムネが並んでおりますが…)、ざっと見た傾向として
- 明らかに k_dpm_2_a と k_eular_a は他のSamplerと比べると出力される絵が異なる
- その他のSamplerは正直似たり寄ったりというところがあるが、たまに細部の出力結果が異なってくることがある
- 絵のタッチがSamplerごとに異なる、ような気がする
Sampler単体をとっかえひっかえして評価するものではなく、他のパラメーター(主にSampling Steps, CFG Scale)と組合せて評価するもんなんでしょうなぁ、という印象でした。
長すぎるpromptは削ってる疑惑
一部のpromptで実行すると、コンソールの出力にwarningが出ています。

Warning: too many input tokens; some (6) have been truncated:
art , trending on artstation
とのこと カンマも一文字とカウントして70wordsを超えるwordは切り落とされるみたいだ こりゃカンマ削らないといかんマジで(渾身のダジャレ)
prompt 1
以下のパラメーターを固定する。
prompt:
Digital Matte painting. Hyper detailed. City in ruins. Post-apocalyptic, crumbling buildings. cyberpunk. Seattle skyline. Golden hour, dusk. Beautiful sky at sunset. High quality digital art. Hyper realistic.
Sampling Steps: 50
CFG scale: 7.5
以下の画像は上から seed: 1026820316 ~ 1026820365、右から Samplers = 'PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' と並んでいます。
もう面倒なのでサムネイルをキャプチャして貼り付けよう。本当は生の出力結果を並べて出せればいいんでしょうが… なんかいいやり方はないものかな













prompt 2
以下のパラメーターを固定する。
prompt:
beautiful stunning amazing slightly cloudly sky with various differently colored floating islands made of dirt and sand and stone with many varied rainforest forest desert plants and few little animals, landscape, fantasy, wide angle, sharp image, cinematic, concept art, 3d, photorealistic render, octane render, blender cycles, unreal engine, raytracing, volumetric light, photoshop, lightroom, digital art, trending on artstation
Sampling Steps: 50
CFG scale: 7.5
以下の画像は上から seed: 1026820316 ~ 1026820365、右から Samplers = 'PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' と並んでいます。







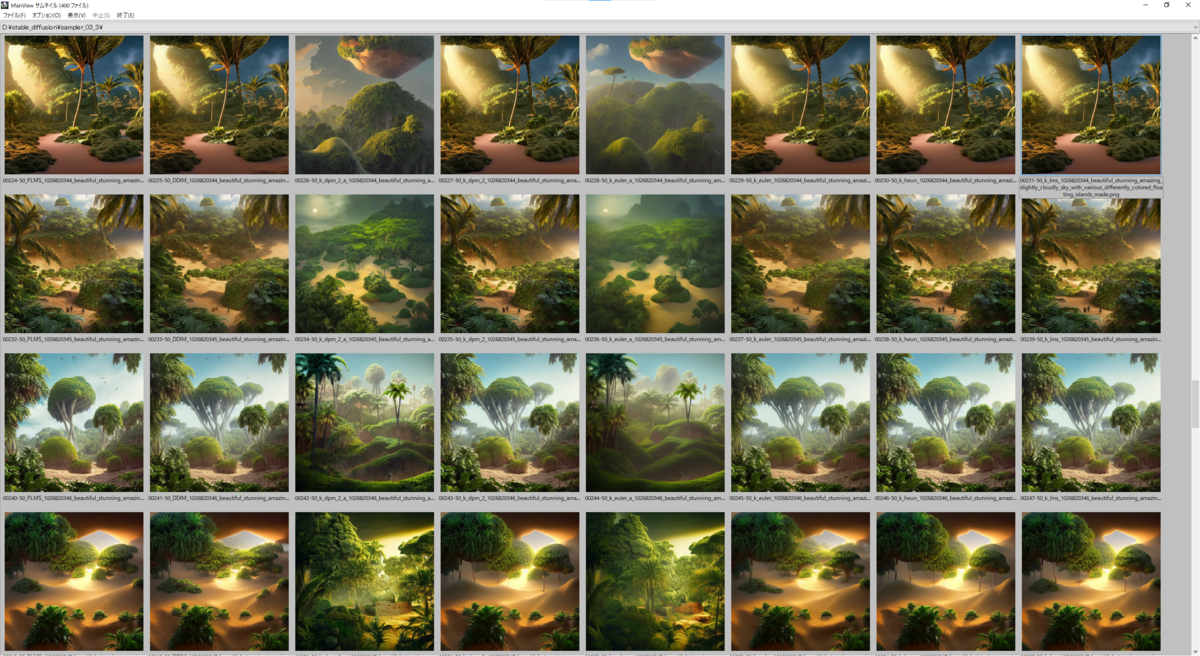


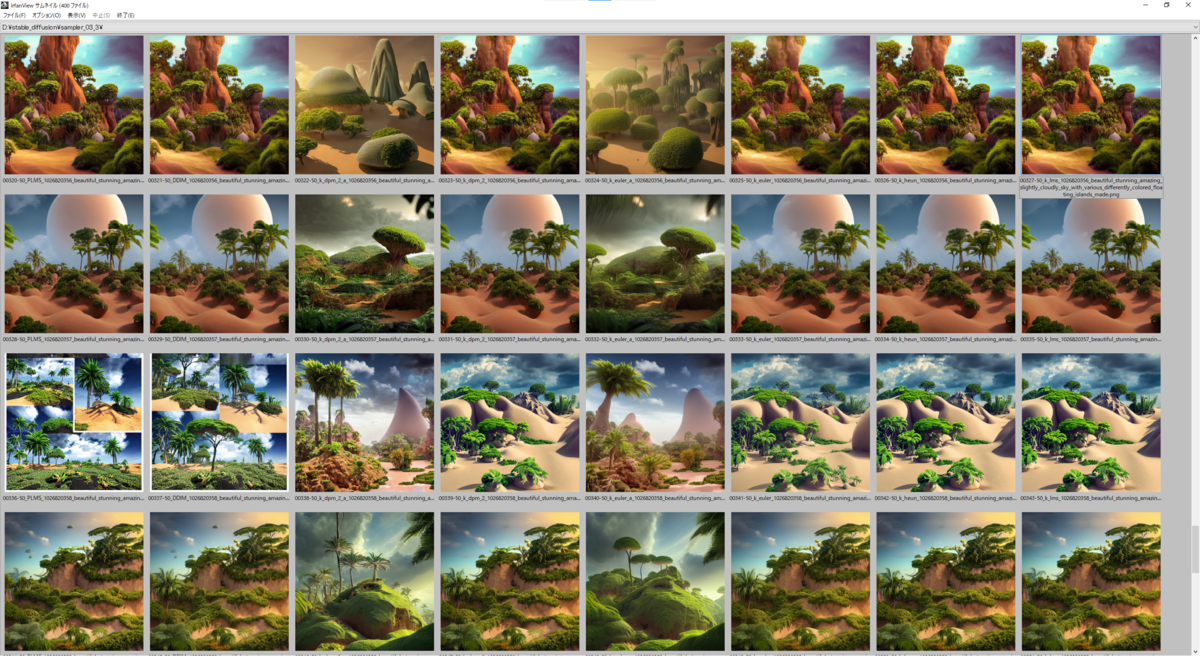


prompt 3
以下のパラメーターを固定する。
prompt:
a picture of robot and drill and girl in maintenance, greg manchess character concept art of an anime goddess of lust | | cute - fine - face, pretty face, realistic shaded perfect face, fine details by stanley artgerm lau, wlop, rossdraws, james jean, andrei riabovitchev, marc simonetti, and sakimichan, tranding on artstation
Sampling Steps: 50
CFG scale: 7.5
以下の画像は上から seed: 1026820316 ~ 1026820365、右から Samplers = 'PLMS', 'DDIM', 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' と並んでいます。









*1:YouTuberの失敗小僧さんがよく言うセリフですが、なるほどこりゃあ便利な言葉だなぁ
Stable Diffusion メモ(5) 絵の描けない人が手を描こうと悪戦苦闘する
やったこと
顔ガチャのやり方がある程度わかったので今度は手を描いてみる。
うまくいかなかったパターン
顔ガチャのときと同じように、手の部分を切り抜いて別画像にし、img2imgをかけることにした。前回の記事と同じやり方。
 →
→ 
この手をimg2imgにかける。

うーん顔に比べると打率が低い… 300連ガチャやって2つか3つくらいか手として見られる絵がない(指が難関)

これはまだ手として見られるものを選ぶことができたが…問題は

こういう元絵が手じゃないやつ。

こんな感じで素人なりに手(指)として見られるよう削りに削ってimg2imgをかけてもまったくもっていいものが出ない。このやり方はダメなのか…
それなりなパターン
もういやんなってきたときにこの記事を見て
そうか元絵全体をimg2imgかけて、手がうまくできた絵から手の部分をもってきて元絵に合成すりゃいいのか… と気づく。いやぁやっぱ長年イラストレーターやってる方の作例は勉強になりますわ… 技術がすごいなぁと思う。
で、

300連ガチャして… 見てみると、元絵が手として成立していない絵から手が生成される確率は非常に低いみたいだ。やっぱ多少の加工は必要か…

これでやってみると…
300連ガチャの結果を動画にいたしました*1


相変わらず確率は低いが、そこそこの手になってる絵が出てくる。この手が出てきた絵全体を元絵にレイヤーとして追加して、不要なところを削ると…

まだ違和感はあるが、少なくとも手の部分を切り抜いてimg2img描けるよりは圧倒的に楽。
顔ガチャしたときは画像サイズは大きければ大きいほど顔の生成結果がよくなっていく傾向があったので切り抜く価値はあったけど、手は切り抜いて拡大しようが元絵のサイズのままやろうが生成結果の打率はそんな変わらない気がした。ので、これでよいんだろう…
なお、img2imgはtxt2imgよりも絵の生成時間が短く、512*768のサイズでも3~4秒程度で生成できる。300連ガチャでも10分ちょい、まだ現実的か。
さらにやってみる
今までやってきた手は人間の手というより機械の手だったからAIには難しかったのかな? と思って人間っぽい絵の手を同じようにかけてみたが、やっぱ手として成立する絵の打率は低いなぁ… なんとかならんもんですか画伯!

指が3本の手を(ちょっと加工して)img2imgかけるとほとんどの絵が指3本になるところ、たまーに指4本の絵が出てくるのがおもしろかったりする。

この4本の指の絵を再度img2imgすると指3本の絵が出てくる確率が明らかに低くなるのでよい*2。img2img -> いい絵を採用、これをもとに(必要に応じて加工して)img2img -> ということを繰り返してよりよい絵を手に入れる、というプロセスが必要になるのだろう… めんどくせー
2回目img2imgの結果を動画にいたしました
きた!KritaのStable Diffusionプラグインきた! これで勝つる!
これ全部KritaのStable Diffusionプラグイン使ったらショートカット一発でやれますわ…
とめっちゃ期待してやってみたところ、KritaのSD Pluginパネルで「Batch count」の値を変更することで最大30連ガチャが可能のようだ。

それぞれの生成結果がレイヤーで積まれるので比較検討をしやすくなりました。うれC

しかし相変わらず打率は低いので、ある程度ガチャを回す必要はありそう。Krita上で完結させるか、これまで書いたやり方で300連ガチャ回すか、どっちが楽なもんか…
しかし手の描写はもっと上手にならんもんなんかな、学習しにくいのかな手って?
Stable Diffusion メモ(4) 絵の描けない人が Krita Plugin で選択範囲にimg2imgかける
これまでやったこと
今回はこれら記事の続き、になるのかな?
Krita と Stable Diffusion Plugin
別画像に切り出してimg2imgするのは面倒だなぁということでGIMPのプラグインの登場を待っていたんですが、どうもKritaという(無料)ペイントツールのプラグインが開発されているということでそちらを利用。
たぶんPhotoshopプラグインと同じことができそう、あちらはどうもクラウド側でimg2imgをするっぽいけど、こちらはローカルでGPUをぶん回すようだ。
導入方法
誰かもっと詳しく書いてください…
(9/4 追記) Krita プラグインがアップデートされ、batファイルを叩けば必要なパッケージを集めてくるようになりました。その代わりにgitが必須となったようです。アップデートにともない、導入方法を書き換えています。
Kritaプラグイン側
- Krita 5.1.0 をインストールする
- Kritaを起動して、メニューから「設定」 - 「リソースを管理」 を選択し、画面の「リソースフォルダを開く」を押す
- エクスプローラが開くので、
pykritaフォルダを開く(なければフォルダを作る) - 取ってきたKrita Pluginのコード一式から krita/plugin 下の krita_diff フォルダとkrita_diff.desktop ファイルを
pykritaフォルダに置く - Kritaを再起動する
- メニューから「設定」 - 「Kritaの設定を変更」 を選択し、画面の「Python プラグインマネージャー」を選択して「Krita Stable Diffusion Plugin」の左にあるチェックボックスのチェックを入れる。
- 「OK」ボタンを押し、Kritaを再起動する。
サーバー側
- Python 3.10.6入れる
- gitをいれる
- CUDA 11.3 を入れる
- git bash を起動し、任意のフォルダで
git clone https://github.com/sddebz/stable-diffusion-krita-plugin.git する- 古いKrita Plugin や webui の実装を上書きせず、別のフォルダにcloneし直すのを推奨
- Stable Diffusionのモデルが置いてあるところ からsd-v1-4.ckptをダウンロードし、model.ckptにリネームした上でwebui.batがあるフォルダと同じところに配置する
- (オプション) GPFGANを使いたい場合は、ここからGPFGANv1.3.pthをダウンロードしてwebui.batがあるフォルダと同じところに配置する
- webui-user.batを実行する(普通に実行すればよい、"管理者として実行"はしないこと)
なんやらかんやらあってKrita プラグインのサーバー側が起動します。

古いやり方
- Krita 5.1.0 をインストールする(少なくともそれより前のバージョンは動かなさそう)
- Krita Plugin のリポジトリからコードをClone、もしくはzipでとってくる
- fork元のStable Diffusion のインストール方法に従い、webui.pyが実行できるようにする(このあたりは日本語で導入方法を書いてる方がおられると思う)
- anaconda or minicondaが必須、krita pluginで環境変数 %CONDA_PATH% が要求される
- Krita Plugin では追加で以下の実行をする
-
conda env update -n ldo --file environment.yaml --prune
-
- Kritaを起動して、メニューから「設定」 - 「リソースを管理」 を選択し、画面の「リソースフォルダを開く」を押す
- エクスプローラが開くので、
pykritaフォルダを開く(なければフォルダを作る) - 取ってきたKrita Pluginのコード一式から krita/plugin 下の krita_diff フォルダとkrita_diff.desktop ファイルを
pykritaフォルダに置く - Kritaを再起動する
- メニューから「設定」 - 「Kritaの設定を変更」 を選択し、画面の「Python プラグインマネージャー」を選択して「Krita Stable Diffusion Plugin」の左にあるチェックボックスのチェックを入れる。
- 「OK」ボタンを押し、Kritaを再起動する。
使用方法
- krita.cmd を実行する
- Krita を起動する
- Stable Diffusionにかけたい画像の範囲を選択する。

- SD Pluginのドッキングパネルでいろいろ設定する or krita_config.yamlをいじる
ドッキングパネルはメニューの「設定」-「ドッキングパネル」-「SD Plugin」にチェックを入れると出てきます。

大抵の設定の優先度は SD Pluginドッキングパネルの設定 > yamlの設定 のようだ
最初yamlで denoising_strengthを設定しても全然効かなくてなんだこれはとウンウン悩んでいましたが、ドッキングパネルを出してなかっただけでした… - Kritaの画面でCtrl + Alt + Q (txt2img) または Ctrl + Alt + W (img2img) を押す
オーできた すげー
自分のマシン(Ryzen 7 5800x, 64GB, RTX 3080 GAMING Z TRIO 12G)で一押し3秒くらい。ウォーはかどりますなぁこりゃ…
Krita自体もGIMPと比べると使いやすい感じする、今後はこちらを使っていくかぁ
たぶん絵を描く人は顔じゃなくてほかのところをtxt2imgなりimg2imgなりかけて変更したいんだろうけど、ほかのところでもこのやり方でいけそうですな。顔ばっかりじゃなくて今度は手を描いてみましょうかな…
いやー楽、これまでの苦労は一体なんだったんだっていうくらい楽
選択範囲をimg2imgした結果がレイヤーで積み重なるってのがいいですな、見比べるのが楽
img2img後にできるレイヤーを表示したままで再度img2imgすると、img2imgした後の画像で再度img2imgをかけるので、より洗練される感じになりそう 元絵から再度img2imgしたい場合はレイヤーを不可視化する必要がありますね。
(9/4 追記)inpaintingできるようになってました
続き
手を頑張って描きました(画伯が)
Stable Diffusion メモ(3): 絵の描けない人が顔ガチャを敢行する
やりたいこと
この前の記事で、
元絵そのままimg2imgにかけると
しかし背景含めて全体が変わってしまうのは不都合が出できそう、画像の指定箇所のみ再度描き直すなんてことができるとたいへん便利になりますなぁ… Photoshopとかで切り抜いてやればうまくいったりするんだろうか?
というアイデアが浮かんだので実際にやってみることにした。
元の絵の一部、今回は顔の部分だけを抜き出して、そこだけimg2imgにかけたらどういう結果が得られるか。
やったこと(1)
この絵の顔を

GIMPで顔だけ抜き出しまして(投げ縄ツールとかウン年ぶりに使った というかGIMP自体ウン年ぶりに使った…)

透過PNGで保存、prompt は前回、前々回とまったく同じでimg2imgをかけます、と次のようなエラーが…
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 6 but got size 5 for tensor number 1 in the list.
うーんようわからんな、いや確か前にStable Diffusionが扱える画像のサイズはどっちかの辺が512pxでないとなんかうまくいかないとか聞いたことがあるな… ではPillowのImage.resizeを使って…
init_image = Image.open(FILE_NAME)
init_image = init_image.convert('RGB')
width,height = init_image.size
resize_image = init_image.resize((512, int(height/width*512)))
こんな感じにして幅を512にして食わせると… オー実行できた

いやーこの生首の並び、禍々しいですな…






うーん、元の顔とタッチが変わってるものが目立ちますなぁ、strength=0.5だとこんなもんなんだろうか… ていうか透過PNGを食わしてるのになんで背景黒なの? あ、さっきのコードでBMPに変換してるからか! PNGのままだとダメなんだっけかな…
まぁいいや、ためしになにか貼り付けてみましょう

うーん、浮くなぁ… やっぱstrength=0.5はかけすぎなんかな、0.3くらいでやってみましょう







オッさっきよりはタッチが元絵と合ってきたんじゃないすか、では何か選んで…

アレなんか浮いてる? なにかしらなじませる方法はあるんだろうけど自分のGIMPスキルは雑コラできる程度のレベルなのでここから先は勉強しないとですかな…
やったこと(2)
オウ次行くぞ次

この顔がちょっと残念な出力結果を…

こうして…
strength=0.3くらいで…

いやこれ結構ええやん…






やっぱ入力を幅512pxまで拡大すると出力もええ感じ
これが… 
オーよくなったぞ! 相変わらず雑コラ感が漂う画像だけども今はこれでも十分満足ですわ
やったこと(3)
さらに顔が小さい画像にいきましょう。
自分は最初はファンタジー調の画像をよく出してたんだけど、ちょっと引きの画像になるとどうしても人物の顔がつぶれまくって、せっかくのいい構図が台無しという悲しい思いをよくしてました… ついにリベンジのときが来たかもしれんぞこれは

これを…

こうして… strengthは元画像が荒すぎるから0.5くらいか…

いやーちょっと異形の生物が誕生しまくってますなぁ… 元画像はさすがにそのまま使えないか。では秘技・素人レタッチを繰り出して…

いや、ここから画伯が我が意を汲んでいい感じで顔を出してくださいますので…
同じくstrength=0.5で…

相変わらず異形の生物は誕生しまくるけど、顔として成立している絵もそれなりに増えてきた! さすが画伯!!!

いや結構よくなってないすか、こりゃあいい!


いやー、いい… 過去の資産(9000枚近い出力結果)が息を吹き返すんじゃないかこれは
ただ…
めんどくさい
自分がGIMPスキルレベル2か3くらいだからなんでしょうが、顔を切り抜いて別画像で保存して出力結果からまた切り抜いて元画像にはめてうんぬんかんぬんが面倒で仕方がない。しかも選んだものが当てはめてみるとしっくり来なくて再度選んでとかちょくちょく発生するので面倒で面倒でしかたがない。なんかGIMPで適当に選択してそこからStable Diffusionにかけて出力結果からパラパラ選んではめてみる、みたいなプラグイン、誰か作っていただけませんでしょうか……!!!!!
Redditとかで絵を作ってる人の例を見ると、txt2imgとtxt2imgの間に適当に色を塗ってimg2imgで補完させながら絵を描く例があったけど、www.reddit.com
このimg2imgやってる箇所みたいな感じで、顔の部分だけ選択範囲にしてimg2imgかけたいなぁ。
参考情報
1枚当たりの出力速度
strengthの値(大きければ遅くなる)とおそらく元画像の荒さによるんだと思いますが、自分のマシン(Ryzen 7 5800x, メモリ64GB, RTX 3080 GAMING Z TRIO 12G)で1枚1秒~4秒くらい。200連ガチャかけて出力結果待ちするのは、なんかビルド待ちでコーヒー汲みに行くプログラマーみたいな感覚になりますね。
切り抜き後の画像サイズ
半端なサイズにすると、リサイズかけて512pxにしても
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 12 but got size 11 for tensor number 1 in the list.
とか出ることがあったので、10の倍数にしといた方が無難かと。 はてなブックマークでコメントいただきましたが、64の倍数がよいですね。id:onigiri-chan さん、ありがとうございます!
続き
Krita Plugin で顔ガチャがはかどりそうなので導入記事を書きました
Stable Diffusion メモ(2): 絵の描けない人がimg2imgでいろいろやる
昨日の続き。
やはり構図を決めるにはimg2imgや、と思い立つ
promptとキャンバス縦横比とかで構図のコントロールに挑戦したけど、いやこりゃ無理だわやっぱ構図を自分で決めるならimg2imgでいろいろ指定してやらないといかんのだろな、ということでimg2imgを導入する。
導入
導入方法は各所で上がっていますが、自分は↓のコードをコピペして、
↓ のコードを参考に実行をしました。
Hな方々は↓を(トラバ含めて)参照し、safety_checkerを切りましょう。変更箇所はStableDiffusionPipelineとほとんど同じです。
絵が描けないので
img2img(1): 全身立ち絵
絵を用意しよう、なんだけどどう用意するか。
まず思いついたのはポーズ集。
こちらのサイトからお借りしました。

これを食わせればこのポーズにあった絵が出るようになるのかな? 実行してみましょう(以下すべて、promptは前回記事と同じ)
結果

いやなんか思ってたんと違うなぁ…



strength=0.8なので元の絵を結構無視するのはいいとしても、これは元絵が素描と近いので素描っぽいもんが出力されたということなんかな
うーむ、これはこれでおもしろいんだけど求めているのはコレではないぞ、ウーム困った…
白いのがダメなんだろか、そしたら色を塗ってみるとまた違うかな?
素材集のポーズ画像に色を塗って
とりあえずmspaintで塗りまして…

ってこれ、使わせてもらったものにこんな適当さで大変申し訳ありません…
さてコレで strength=0.8で実行すると…
結果
おおっこれ意外と結構いけるんじゃないの






strength=0.8なので元絵の構図から大きく変わることがあるものの、さっきの無色のときにくらべたらまだ元絵に合わせてくれてる方だと思う
顔が崩れる絵が多くなるのはどうもキャンバスの面積に比べて顔の面積が小さい場合は崩れやすいらしく、twitter等で報告多数。うーん、じゃあ今度は顔が大きめの画像でやってみましょうか
img2img(2): クローズアップ
今度はこちらのサイトからお借りしました。
また色を塗りまして…

…素材をまったく生かせず大変申し訳ありません… で実行をします
結果
おおっこれもなかなか






一部その発想はなかった的なものもありますが、手がなくなりがちということを除けば顔の傾きを含めてわりと元絵を尊重いただいております。顔の崩れはそこそこあるものの、やはり元絵の顔が大きいと破綻を来すような大きな崩れは少なくなってくる様子。
元絵なしでやる
txt2img->img2img(1)
しかし自分のほしい構図がいつも素材集にあるとは限らないし、そもそもどんな構図がグッとくるのか自分でもよくわからないことがある。その場合はいっぺんpromptのみを指定してtxt2imgで実行、出力結果を眺めてグッと来たものをブラッシュアップすればよいのではと思い立つ。
前回の記事で出力した横長の画像の中からこれがグッと来たとして、
ちょっと左肘の出っ張りはいらないなぁということでまたmspaintで消して、
コレを元絵としてimg2imgを実行すると(prompt は元絵と同じ(前回記事参照)、strength=0.5)
結果

strength=0.5だとどれも元絵の構図に合わせてきますね。サムネイルだとパッと見で見分けがつかない程度に…






気に入る絵が出るまでガチャしまくれば、納品前の修正依頼が多すぎる発注者もニッコリだったりするんですかね……
しかし背景含めて全体が変わってしまうのは不都合が出できそう、画像の指定箇所のみ再度描き直すなんてことができるとたいへん便利になりますなぁ… Photoshopとかで切り抜いてやればうまくいったりするんだろうか?
txt2img->img2img(2)
出力した結果ちょっとクローズアップしたい/引きたい場合も
 これを
これを
 こうして
こうして
それでimg2imgにかけると(prompt は元絵と同じ、strength=0.5)
結果







元絵も同じpromptで出力しているからか、ほとんど崩れないですねぇ… 安心して当たり画像が出るまで300連ガチャとかできます(?)
img2img->img2img
そしたら素材集からimg2imgで生成した画像も再度img2imgをかけると…



小さい顔の場合でも当たりが出るまでウン百連とガチャを回せばいいのが出るかもしれないけど、まぁ現実的ではないでしょうな… 現時点では自分で顔の部分だけでも手直しするのが手っ取り早いのでしょう、だがしかし、それが無理だから自分はこうやってこねくり回しているわけですけれども……
続き
Stable Diffusion メモ: キャンバスの縦横比は構図にどれくらい影響するか
Stable Diffusion が公開されてからいろいろ動かして出力の傾向を見てみようとしたメモ。
やったこと
同じpromptを指定して、
- 縦長(512x768)
- 横長(768x512)
- 正方形(512x512)
のサイズごとにそれぞれ200枚ずつ出力、それら画像の傾向を見て構図にどんな変化があるかを確認しようとした。ザッと見の印象、感触のみで評価し、定量評価はしない。
使用したプロンプト:
a picture of robot and drill and girl greg manchess character concept art of an anime goddess of lust | | cute - fine - face, pretty face, realistic shaded perfect face, fine details by stanley artgerm lau, wlop, rossdraws, james jean, andrei riabovitchev, marc simonetti, and sakimichan, tranding on artstation
↑の元として参考にさせてもらったプロンプトはこちら
結果
縦長(512x768)
ザッと見の印象で、
- ウエスト、膝丈、全身の姿が描かれることが多い
- 背景はあまりない
- 顔の崩れはすくない
作例:






横長(768x512)
ザッと見の印象で、
-
バストアップも多くなる
-
1つの絵の中に2人描かれる確率が非常に高い
-
背景が描かれる絵が多い
-
縦長に比べて顔が崩れる絵が多くなる
顔崩れが多くなるのは気になる、背景込みの学習データがノイズになるんだろうか?
作例:







正方形(512x512)
- 傾向としては縦長の出力に似ている 縦長の出力を上下切り取った感じ?
- しかし横長の構図に似ているものも見られる
バストアップ多め、クローズアップも見られる
作例:







思ったこと
学習データの構図の傾向に引き寄せられるかたちで生成結果の構図も決まってくるのかなぁという気はした(縦長は背景無地のポートレート、横長は背景のなかにキャラクターがいる絵とか)。自分の得たい絵の構図に合わせてキャンバスの縦横比を検討するのも必要そうだ。
その他メモ
1枚あたりの作成速度
CPU: Ryzen 7 5800
MEM: 64GB
GPU: RTX 3080 Gaming Z TRIO 12G
縦長横長 1枚9~10秒
正方形 1枚5~6秒
promptを大幅に変更してから初回の作成は、3~40枚ほどは1枚につき20秒~1分ほどかかった。アーキテクチャはよくわからないけど、最初は機械学習のモデル? を生成しながら描画でもしているのだろうか… 40枚くらい描き終わるとあとは1枚9~10秒程度に落ち着いた。
オーバークロックをもとからやってるグラボだからか、描画中はGPUの温度が85℃、サーマルスロットリングを起こすことも。このままだと壊れそうだしちょっとクロック落とさないと…

その他の作例
爺さん



おっさん


風景と人物




いやほんとにさわってておもしろい!
続き
img2imgに挑戦しました